Parametrização Inicial
O PCdoc Capture adota o conceito de captura em lote de conteúdos documentais. Os parâmetros de configuração iniciais devem ser aplicados ou revistos toda vez que um novo lote for trabalhado, pois pode haver alteração da necessidade ou da forma de indexação de um lote para outro.
Modelo de Conteúdo
Antes de iniciarmos as configurações, alguns conceitos são importantes para a compreensão das operações que faremos mais adiante, são eles: Modelo de Conteúdo, Tipo de Conteúdo, Propriedade do Tipo de Conteúdo, Tipo de Propriedade e Aspecto. Estão relacionados conforme mostrado na figura 1.
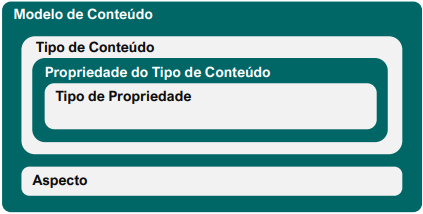 Figura 1 – Elementos do modelo de conteúdo
Figura 1 – Elementos do modelo de conteúdo
Com um exemplo simples vamos entender rapidamente esses conceitos. A princípio temos que ter em mente que a aplicação desses conceitos são para a construção de um modelo de dados para identificar os documentos que serão armazenados na plataforma.
Vamos usar um cenário de uma empresa de varejo chamada Varejo Ltda que adotou a plataforma para gestão de seus conteúdos arquivísticos. Assim, o Modelo de Conteúdo desta empresa poderia ser a própria abrangência da empresa ou uma de suas áreas que produzem documentos específicos. O Tipo de Conteúdo seriam os departamentos da empresa (Recursos Humanos e Financeiro).
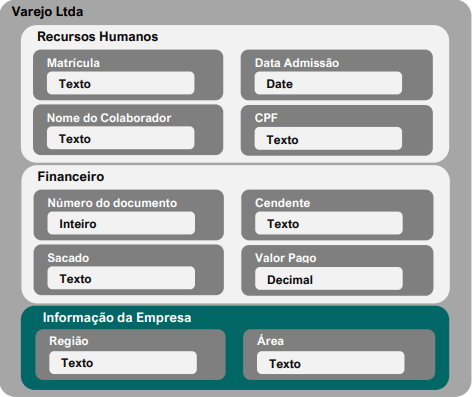 Figura 2 – Modelo de dados da empresa Varejo LTDA.
Figura 2 – Modelo de dados da empresa Varejo LTDA.
As Propriedades dos Tipos de Conteúdo, seriam os campos (metadados) de informação sobre os documentos (Recursos Humanos: Matrícula; Nome do Colaborador; Data de Admissão e CPF; Financeiro: Número do documento; Sacado; Cedente e Valor Pago).
O Aspecto seria um tipo especial de conteúdo (Informação da Empresa) cujo propósito também é armazenar informações sobre os documentos, contudo, suas propriedades podem ser reaproveitadas nos demais tipos de documentos, bastando para isso, ser herdado pelo tipo de conteúdo desejado, vamos ver esse procedimento no tópico “Importar Modelo” mais a diante.
Empresa
No cadastro da empresa serão concentrados todos os processos de classificação e indexação de documentos. Então é o primeiro cadastro que deve ser realizado. Clique no menu “Arquivo” e selecione a opção “Empresa”.
 Figura 3 – Lista de Empresas.
Figura 3 – Lista de Empresas.
A partir do registro da empresa, é possível configurar vários outros parâmetros iniciais para iniciar os trabalhos com os lotes de documentos. A figura 6 mostra a tela de cadastro de empresa onde são exibidos os atributos: Fantasia(Nome Fantasia), CNPJ, Razão Social URL e Ativo.
São exibidos também os grupos Diretório de trabalho e Tipologias. No primeiro é necessário informar qual diretório (pasta) será o diretório raiz a partir do qual todos os lotes ficarão concentrados. No grupo Tipologias, é possível importar o(s) modelo(s) de arquivos criados do PCdoc Share.
Ainda nesta tela, é possível iniciar o cadastro de lotes. Veremos esse tópico em “Criação do lote de trabalho” mais a diante.
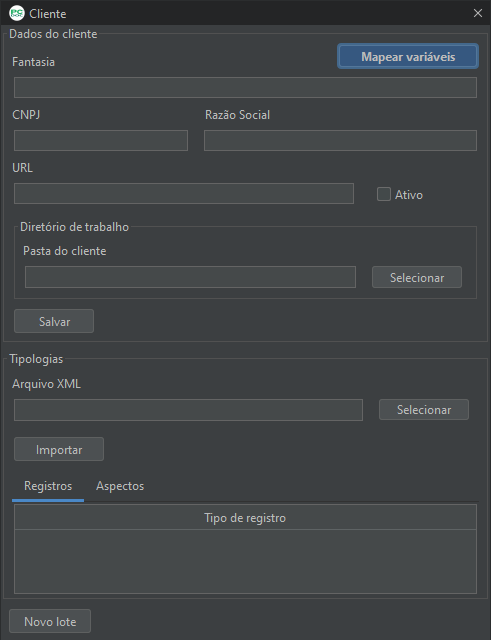 Figura 4 – Cadastrar Empresa.
Figura 4 – Cadastrar Empresa.
Metadados de Autoria e Arquivístico
Antes, porém, existe uma configuração importante a ser feita que vai permitir o compliance com a legislação brasileira sobre o processo de digitalização. Clique no botão “Mapear variável” no canto superior da tela conforme mostrado na figura 6 acima.
Nesta janela de configuração, são apresentados os metadados mínimos que são exigidos pelo Decreto 10.278, de 18/03/2020, o qual estabelece e define técnicas e requisitos mínimos para a digitalização de documentos públicos ou privados.
De acordo com esse regramento, todos os documentos em formato digital devem possuir no mínimo os seguintes metadados de autoria e identificação, são eles:
| Metadados | Definição |
|---|---|
| Assunto | Palavras-chave que representam o conteúdo do documento. Pode ser de preenchimento livre ou com o uso de vocabulário controlado ou tesauro. |
| Autor (nome) | Pessoa natural ou jurídica que emitiu o documento. |
| Data e local da digitalização | Registro cronológico (data e hora) e tópico (local) da digitalização do documento. |
| Identificador do documento digital | Identificador único atribuído ao documento no ato de sua captura para o sistema informatizado (sistema de negócios). |
| Responsável pela digitalização | Pessoa jurídica ou física responsável pela digitalização |
| Título | Elemento de descrição que nomeia o documento. Pode ser formal ou atribuído: • Formal: designação registrada no documento; • Atribuído: designação providenciada para identificação de um documento formalmente desprovido de título. |
| Tipo documental | Indica o tipo de documento, ou seja, a configuração da espécie documental de acordo com a atividade que a gerou. |
| Hash (chekcsum) da imagem | Algoritmo que mapeia uma sequência de bits (de um arquivo em formato digital), com a finalidade de realizar a sua verificação de integridade. |
Para a gestão arquivística, os seguintes metadados são obrigatórios:
| Metadados | Definição |
|---|---|
| Classe | Identificação da classe, subclasse, grupo ou subgrupo do documento com base em um plano de classificação de documentos. |
| Data de produção (do documento original) | Registro cronológico (data e hora) e tópico (local) da produção do documento. |
| Destinação prevista (eliminação ou guarda permanente) | Indicação da próxima ação de destinação (transferência, eliminação ou recolhimento) prevista para o documento, em cumprimento à tabela de temporalidade e destinação de documentos das atividades-meio e das atividades-fim. |
| Gênero | Indica o gênero documental, ou seja, a configuração da informação no documento de acordo com o sistema de signos utilizado na comunicação do documento. |
| Prazo de guarda | Indicação do prazo estabelecido em tabela de temporalidade para o cumprimento da destinação. |
Na figura 7 podemos visualizar esses campos e configurar a forma com que o sistema irá extrair a informação para associar aos documentos no processo de indexação.
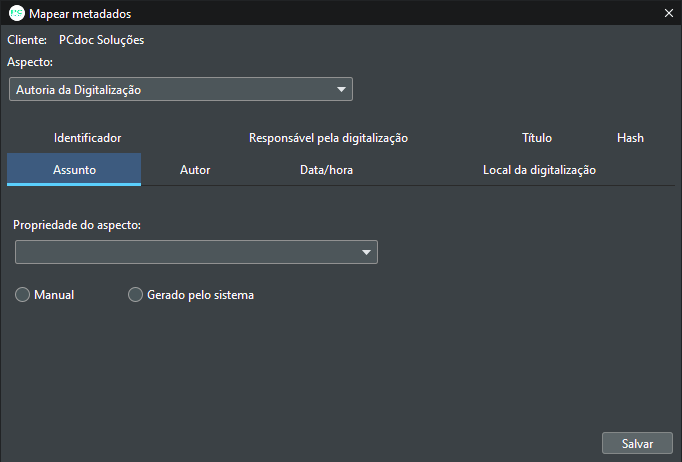 Figura 5 – Mapear metadados.
Figura 5 – Mapear metadados.
Em resumo, temos para cada metadado a opção de associá-lo a um tipo de conteúdo para automatizar o preenchimento automático da informação, ou em alguns casos a possibilidade de extrair a informação do próprio arquivo digital, como é o caso da Data/hora Título e Hash. Também é possível realizar um input manual dessas informações para algum caso bem específico, contudo, não é aconselhável o input manual, visto que o usuário teria que estar vindo nesta tela refazer essa configuração sempre que o tipo de conteúdo mudar no lote que será indexado.
Para que os aspectos de Autoria e de Arquivamento aparecem nesta lista, o usuário deverá acessar através do login na empresa que deseja configurar; em seguida importar o arquivo Sistema.xml, com o seguinte procedimento:
- Clicar no menu Arquivo -> Empresa;
- Selecionar com duplo clique no nome da empresa;
- Em Tipologias, selecionar o arquivo Sistema.xml no disco;
- Clicar no botão “Importar“. Após este procedimento, é possível mapear esses aspectos conforme figura 7.
Importar Modelo
O modelo, como já explicado, é o conjunto de tipos de conteúdo criado no PCdoc Share para classificar cada conteúdo e prepará-lo ou indexá-lo para pesquisas futuras. Depois de modelar os tipos documentais e exportá-lo no formato XML, acesse o menu Arquivo -> Empresa, duplo clique no nome da empresa

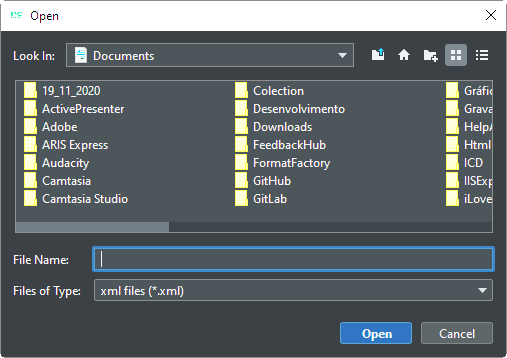 Figura 6 – Janela para importar modelo XML.
Figura 6 – Janela para importar modelo XML.
Clique no botão Selecionar (grupo Tipologias) e aponte para o arquivo de modelo XML que exportou do PCdoc Share. Caso o modelo já tenha sido importado anteriormente, uma mensagem será mostrada com a opção de atualizar o modelo com os dados do arquivo atual.

Configurar Nomenclatura dos Documentos
Após a importação do modelo, é possível configurar a renomeação dos documentos do lote que será trabalhado utilizando os campos do tipo documental (Figura 9). Essa parametrização deixará os nomes dos arquivos mais intuitivos antes de subir para o repositório.
 Figura 7 – Janela de configuração de nomenclatura.
Figura 7 – Janela de configuração de nomenclatura.
Selecione a propriedade que deseja associar ao nome do arquivo, pode ser mais de uma, e no momento da renomeação o sistema irá concatenar essas propriedades para formar o nome do documento. Caso haja mais de um documento com o mesmo nome na pasta, será acrescentado um contador sequencial ao final do documento
Importar Lista Externa
Outra configuração que pode automatizar, consideravelmente, o processo de indexação é a possibilidade de importar uma lista externa para o sistema para associá-la ao tipo documental que será indexado Clicando no menu Arquivo -> Importar Lista, acessamos a tela da Figura 8.
 Figura 8 – Importar lista.
Figura 8 – Importar lista.
Entre com um nome para a tabela, em seguida clique no botão “Importar”. Mais adiante, no processo de Classificação, essa tabela com seus campos poderão ser associados às propriedades do Tipo de Registro (tipo de conteúdo). Essa associação é um mapeamento entre cada metadado de índice do arquivo com os dados que serão cadastrados neles no processo de indexação.
Na figura 9 podemos visualizar como será feito esse mapeamento:
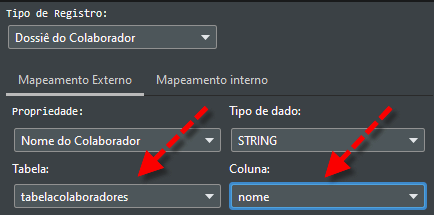 Figura 9 – Tabela importada da lista externa sendo associada ao Tipo de Registro.
Figura 9 – Tabela importada da lista externa sendo associada ao Tipo de Registro.
Tipo de Mapeamento
Essa configuração indicará ao sistema onde será a origem dos dados que serão extraídos para popular os metadados do tipo de registro. Clicando no menu Configurações -> Tipo de mapeamento, acessamos a tela da Figura 10. Será necessário informar ao sistema se os campos de índice serão alimentados com informações de uma tabela ou do próprio documento. Esse tipo pode ser das seguintes formas:
 Figura 10 – Janela Configurar tipos de mapeamento.
Figura 10 – Janela Configurar tipos de mapeamento.
O Tipo de registro é o tipo de conteúdo presente no modelo que foi importando do PCdoc Share e agora é possível ser utilizado para classificar documentos por categorias de conteúdo.
Exemplo: Uma Nota Fiscal de Venda é uma categoria fiscal de documento que classifica esse tipo de informação.
O Tipo de mapeamento é a forma como o programa irá buscar os dados para popular as propriedades do Tipo de registro. Conforme veremos a seguir, o Tipo de mapeamento pode ser:
- Mapeamento Externo: Neste caso é possível associar uma tabela do sistema, que foi constituída através da importação de dados de uma lista externa (planilha do MS Excel).
- Mapeamento Interno: Nesta opção o programa será instruído a buscar os dados da extração de dentro dos próprios documentos, através de expressões regulares (regex).
- Mapeamento Nomenclatura: Neste caso o mapeamento é feito através do próprio nome do arquivo, que já contém os dados para extração, tais como: CPF, Nome do colaborador, Data, etc.
Configurar Capa de Documento
No processo de indexação é possível criar e inserir em cada documento (na etapa de preparo) uma capa de documento. Essa capa servirá como um separador de cada documento e ao mesmo tempo indexador para o sistema “entender” qual será a tipologia do documento na indexação. Clique no menu Configurações -> Capa de Documento.
Figura 11 – Capa de documento.
É possível editar a quantidade de separadores que serão impressas em cada página no formato A4, com o máximo de 4 etiquetas por página.
Um duplo clique no nome do tipo documental da lista irá mostrar a janela da figura 14 com a opção para imprimir a(s) capa(s) de cada documento que será escaneado.
 Figura 12 – Impressão da capa de documento.
Figura 12 – Impressão da capa de documento.